|
|

|
Methods for Autonomously Decomposing and Performing Long-horizon Sequential Decision Tasks Shubham Pateria[DR-NTU] Ph.D. Thesis in Digital Repository of NTU, 2022. |
|
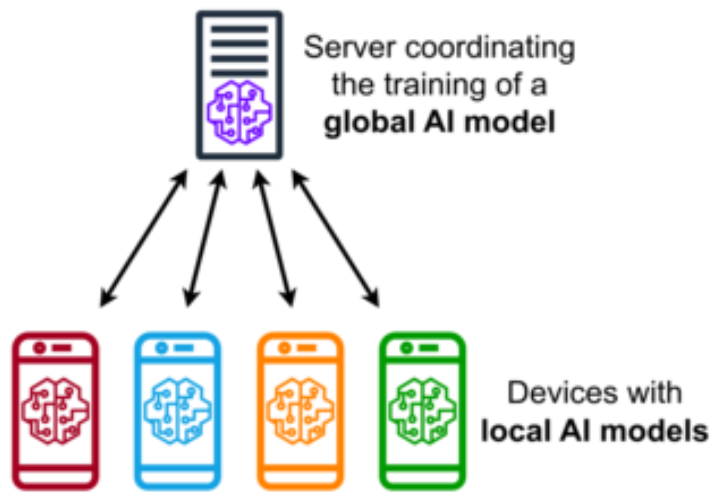
Shubham Pateria, Budhitama Subagdja, Ah-Hwee Tan. [Under Review] Details coming soon. This work is a part of the Trustworthy Federated Ubiquitous Learning project under SMU and AISG. Developing a novel self-organizing federated learning system for distributed data clustering, classification, and vertical federated learning. The system outperforms baselines by 25% in sparse data clustering and 3-4% in biomedical classification. |
|
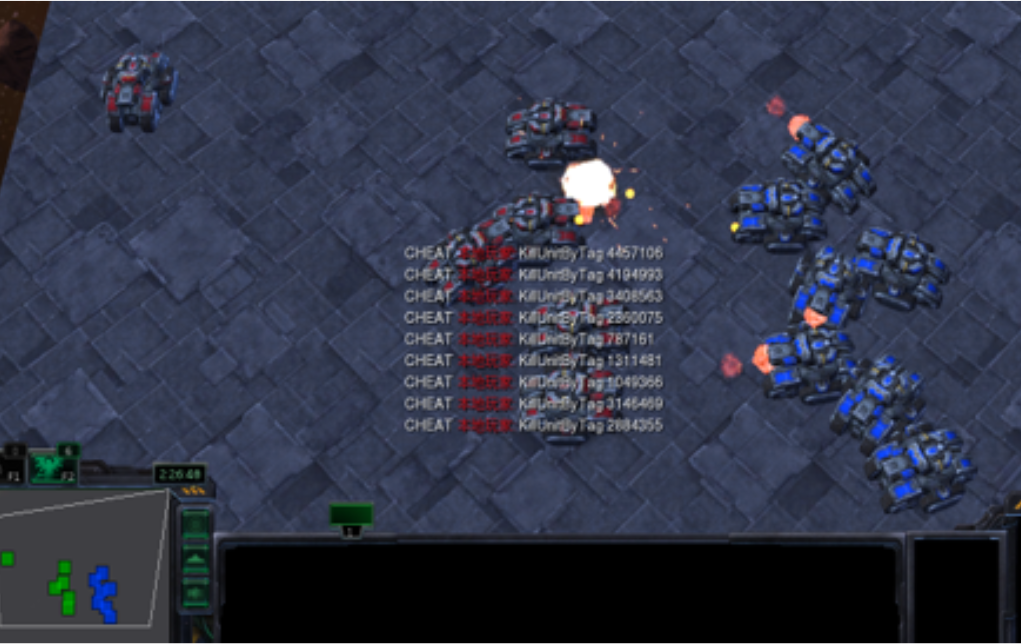
Minghong Geng, Shubham Pateria, Budhitama Subagdja, Ah-Hwee Tan. [Confidential] Licensed to DSO National Laboratories, Singapore in 2023. A hierarchical multi-agent reinforcement learning system combining self-organizing and deep neural networks, for simulated defense research technology licensed to DSO National Laboratories. The codes and documentation related to this research are currently confidential. |
|
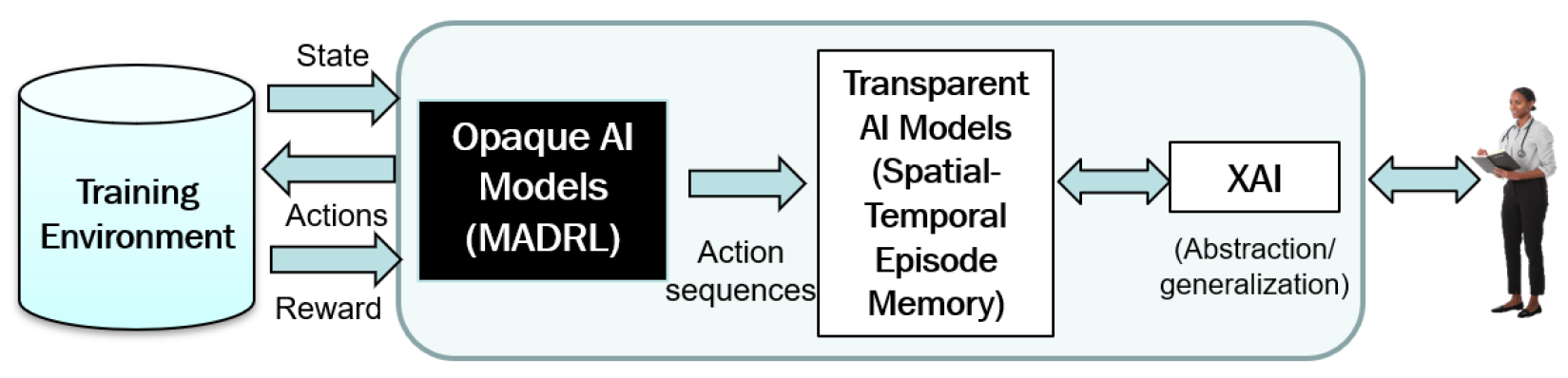
Towards Explaining Sequences of Actions in Multi-Agent Deep Reinforcement Learning Models Khaing Phyo Wai, Minghong Geng, Budhitama Subagdja, Shubham Pateria, Ah-Hwee Tan.
[AAMAS 2023] In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems (AAMAS '23), IFAAMAS, Richland, SC, 2325–2327. [ poster] A novel approach to explain Multi-agent Deep Reinforcement Learning (MADRL) by transforming sequences of action events performed by agents into high-level abstract strategies using a spatio-temporal neural network model. |
|
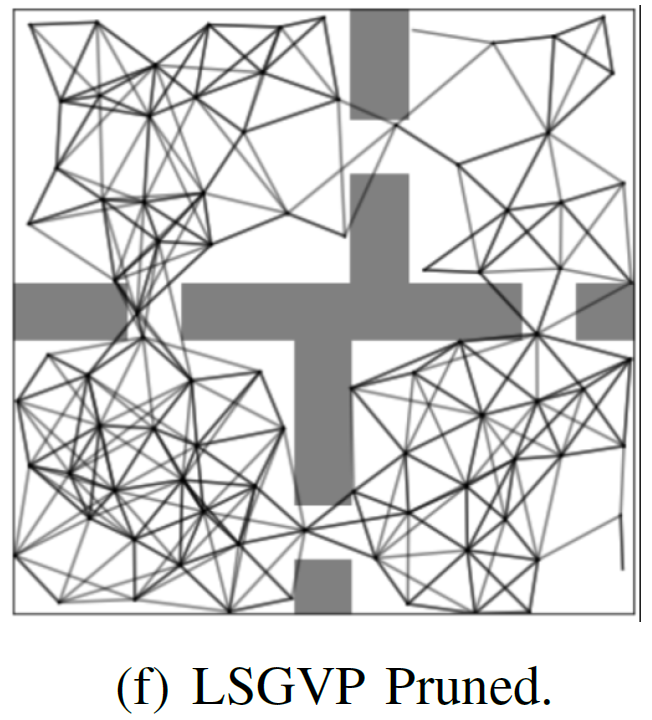
LSGVP: Value-Based Subgoal Discovery and Path Planning for Reaching Long-Horizon Goals Shubham Pateria, Budhitama Subagdja, Ah-Hwee Tan, Chai Quek.
[IEEE TNNLS 2023] In IEEE Transactions on Neural Networks and Learning Systems, doi: 10.1109/TNNLS.2023.3240004; (Impact Factor: 14.255). LSGVP is a subgoal-graph planning method for goal-based navigation and simulated robot control. It uses a subgoal discovery heuristic that is based on a cumulative reward (value) measure and yields sparse subgoals, including those lying on the higher cumulative reward paths. Moreover, LSGVP guides the agent to automatically prune the learned subgoal graph to remove the erroneous edges. The combination of these novel features helps the LSGVP agent to achieve higher cumulative positive rewards than other subgoal sampling or discovery heuristics, as well as higher goal-reaching success rates than other state-of-the-art subgoal graph-based planning methods. |
|
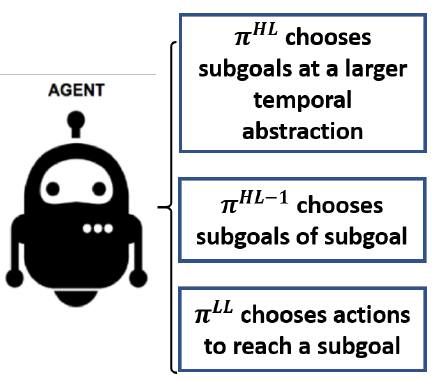
LIDOSS: End-to-End Hierarchical Reinforcement Learning With Integrated Subgoal Discovery Shubham Pateria, Budhitama Subagdja, Ah-Hwee Tan, Chai Quek.
[IEEE TNNLS 2022] In IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 12, pp. 7778-7790, Dec. 2022, doi: 10.1109/TNNLS.2021.3087733; (Impact Factor: 14.255). [ paper] LIDOSS is an end-to-end Hierarchical Reinforcement Learning (HRL) method for goal-based navigation and simulated robot control. It introduces a subgoal discovery heuristic that narrows down the search space for the higher-level policy by focusing on subgoals that are more likely to occur in state-transitions leading to the goal. Evaluated against a state-of-the-art HRL method called Hierarchical Actor Critic (HAC), LIDOSS demonstrates improved goal achievement rates across various continuous control tasks. |
|
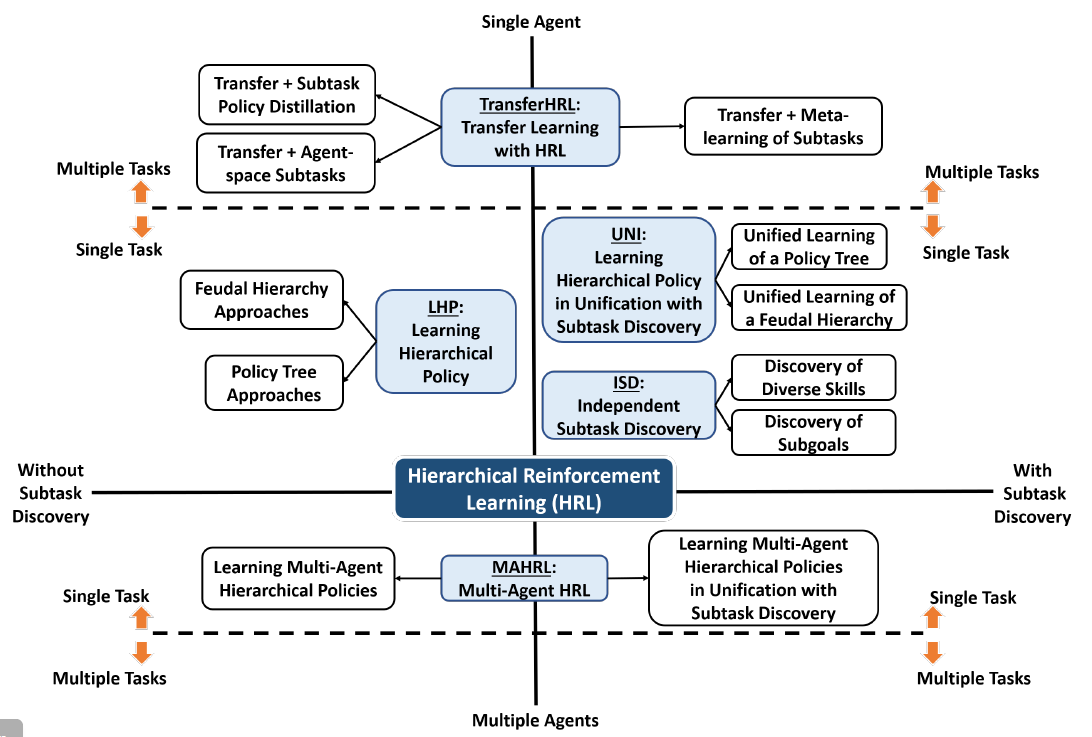
Hierarchical Reinforcement Learning: A Comprehensive Survey Shubham Pateria, Budhitama Subagdja, Ah-Hwee Tan, Chai Quek.
[ACM CSUR 2022] In ACM Computing Surveys 54, 5, Article 109 (June 2022), 35 pages. https://doi.org/10.1145/3453160; (Impact Factor: 14.324). [ paper] We provide a survey of both foundational as well as recent Hierarchical Reinforcement Learning (HRL) approaches concerning the challenges of learning hierarchical policies, subtask discovery, transfer learning, and multi-agent learning using HRL. The survey is presented according to a novel taxonomy of the approaches. Based on the survey, a set of important open problems is proposed to motivate the future research in HRL. |
|
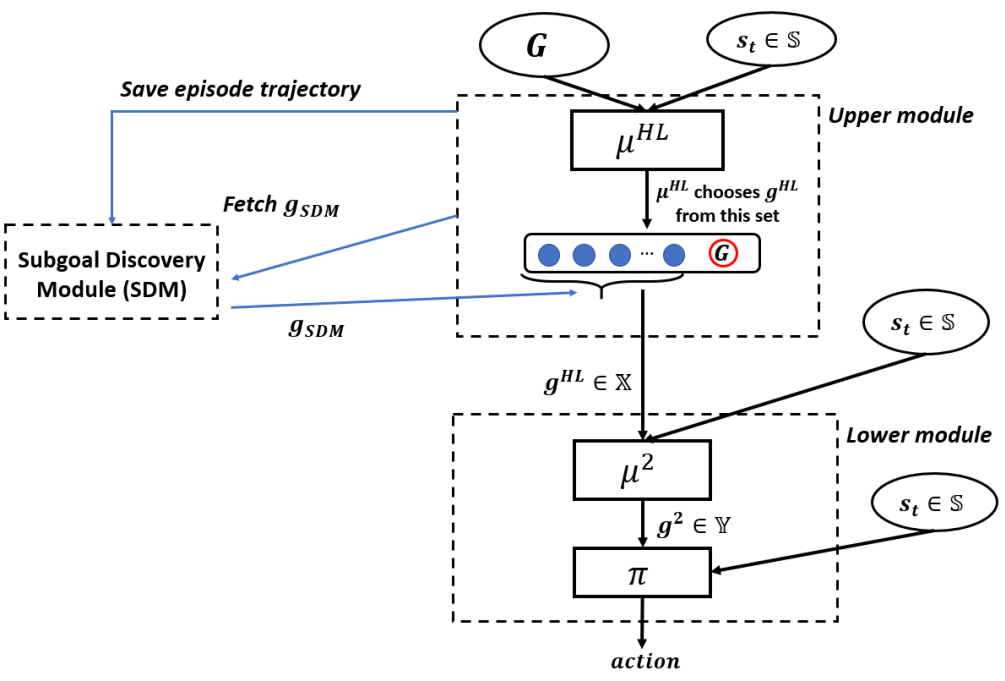
Hierarchical Reinforcement Learning with Integrated Discovery of Salient Subgoals Shubham Pateria, Budhitama Subagdja, Ah-Hwee Tan.
[AAMAS 2020] In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS '20). IFAAMAS, Richland, SC, 1963–1965. [ paper] |
|
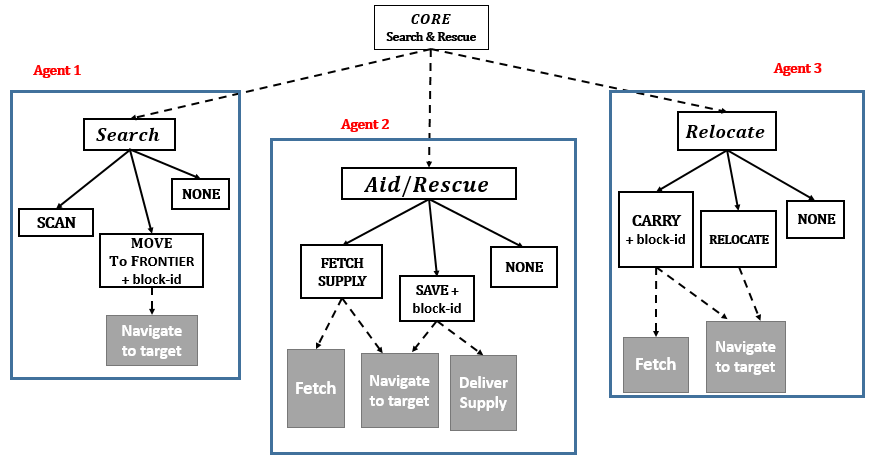
Shubham Pateria, Budhitama Subagdja, Ah-Hwee Tan.
[IEEE SSCI 2019] In IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 2019, pp. 86-93, doi: 10.1109/SSCI44817.2019.9002777. [ paper] [ codes] [ code documentation] ISEMO is a Multi-agent Hierarchical Reinforcement Learning (MAHRL) that uses an Inter-Subtask Empowerment Reward (ISER) to facilitate cooperation among agents in complex tasks, where some agents are essential for reaching rewarding states while others play supporting roles. ISER complements task rewards, enhancing inter-agent coordination, and ISEMO includes an options model to learn subtask termination functions, improving flexibility compared to hand-crafted conditions. Experiments demonstrate that ISEMO effectively learns subtask policies and terminations, outperforming standard MAHRL in a spatial Search and Rescue scenario. |